
はじめに:インデックス設計が重要な理由
PostgreSQLのパフォーマンスを左右する最大の要素の一つが「インデックス設計」です。
インデックスは検索を高速化する便利な仕組みですが、「とりあえず作る」では逆効果になることもあります。
本記事では、「どんなときにインデックスを設定すべきか」「どのように設計すべきか」を、設計方針を軸にわかりやすく解説します。
インデックスとは何か?基本の仕組みを理解する
インデックスとは、データベース内で検索を高速化するための補助的なデータ構造です。
PostgreSQLでは主にB-treeインデックスが使われ、テーブルの特定列をもとに木構造を作成します。
CREATE INDEX idx_members_customer_id ON project_members(customer_id);上記のように作成することで、customer_idの検索が高速になります。
ただし、インデックスは万能ではなく、更新コストやストレージ負荷も増えるため、設計段階での判断が非常に重要です。
【判断基準】インデックスを設定すべきかの見極め方
3-1. WHERE句・JOIN句での使用頻度
SQL文において頻繁にWHEREやJOIN条件に使われる列は、インデックスを設定する候補です。
特に以下のようなケースは設定推奨です。
- 顧客IDやユーザーIDなど、主キー以外で検索される列
- 外部キー制約で他テーブルと頻繁に結合される列
- 特定の状態(例:delete_flg=’0’(未削除))でよくフィルタされる列
逆に、毎回異なる値を検索するような列(例:timestampなど)は効果が薄いことがあります。
3-2. テーブルサイズとデータ更新頻度
インデックスは読み取り性能を向上させる一方で、INSERT・UPDATE・DELETEのたびに更新コストが発生します。
そのため、以下のように判断するのが基本です。
| テーブル特性 | インデックス設定方針 |
|---|---|
| 読み取り中心(参照が多い) | 積極的に設定 |
| 更新中心(頻繁なINSERT/UPDATE) | 必要最小限に限定 |
| 小規模テーブル(数千件以下) | 不要な場合も多い |
3-3. 検索パターンとソート要件
ORDER BYやGROUP BYで頻繁に使う列もインデックス設定の候補です。
特にWHERE + ORDER BYの組み合わせは、複合インデックスを作成することで効率化できます。
CREATE INDEX idx_members_role_joined ON project_members(role, joined_at);このように「検索条件+並び順」に沿ったインデックスを設計することで、実行計画上のSortコストを削減できます。
【設計方針】パフォーマンスを意識したインデックス設計の考え方
4-1. 過剰なインデックスの弊害
インデックスを多く作りすぎると、以下のような問題が発生します。
- 更新系クエリが遅くなる
- ストレージ容量が肥大化する
- PostgreSQLの
ANALYZEやVACUUMの負荷増大
設計時には「目的の明確化」と「定期的な見直し」が必須です。
4-2. 複合インデックスと単一インデックスの使い分け
複合インデックスは便利ですが、順序と利用範囲を意識する必要があります。
例:(customer_id, order_date)
→ customer_idのみの検索には有効だが、order_dateのみの検索では使われない。
複合化しすぎるとメンテナンスが煩雑になるため、実際のクエリを想定して最小構成にとどめるのが設計の基本です。
4-3. 統計情報と実行計画を活用した設計プロセス
PostgreSQLではEXPLAINコマンドを活用することで、インデックスの利用状況を確認できます。
EXPLAIN ANALYZE SELECT * FROM project_members WHERE customer_id = 12345;Index Scanが表示されればインデックスが活用されています。
もしSeq Scan(全件走査)が多発する場合は、インデックス設計を見直す必要があります。
【実践】PostgreSQLでのインデックス設定方法
準備
構成
今回の実践では以下の3テーブルを使います:
| テーブル名 | 役割 |
|---|---|
| customers | 顧客マスタ(親テーブル) |
| projects | プロジェクトマスタ(親テーブル) |
| project_members | プロジェクトメンバテーブル(中間・子テーブル) |
それぞれに主キー・外部キー・インデックスを設定し、JOINや検索を行います。
準備①テーブル作成
顧客マスタ、プロジェクトマスタ、プロジェクトメンバテーブルを作成する(CREATE TABLE文)。
-- 顧客マスタ生成
CREATE TABLE customers (
customer_id SERIAL PRIMARY KEY,
customer_name VARCHAR(100) NOT NULL,
email VARCHAR(200) UNIQUE,
status VARCHAR(20) DEFAULT 'active'
);
-- プロジェクトマスタ生成
CREATE TABLE projects (
project_id SERIAL PRIMARY KEY,
project_name VARCHAR(100) NOT NULL,
start_date DATE,
end_date DATE
);
-- プロジェクトメンバテーブル生成(複合主キー+外部キー)
CREATE TABLE project_members (
project_id INT NOT NULL,
customer_id INT NOT NULL,
role VARCHAR(50),
joined_at DATE DEFAULT CURRENT_DATE,
PRIMARY KEY (project_id, customer_id), -- 複合主キー
FOREIGN KEY (project_id) REFERENCES projects(project_id),
FOREIGN KEY (customer_id) REFERENCES customers(customer_id)
);準備②サンプルデータ投入
顧客マスタ、プロジェクトマスタ、プロジェクトメンバテーブルにサンプルデータを投入する。
-- 10万件のダミーデータを顧客マスタに投入
INSERT INTO customers (customer_name, email, status)
SELECT
'Customer_' || g,
'customer' || g || '@example.com',
CASE WHEN random() < 0.8 THEN 'active' ELSE 'inactive' END
FROM generate_series(1, 100000) AS g;
-- 1,000件のダミーデータをプロジェクトマスタに投入
INSERT INTO projects (project_name, start_date)
SELECT
'Project_' || g,
CURRENT_DATE - (g || ' days')::INTERVAL
FROM generate_series(1, 1000) AS g;
-- 20万件のダミーデータをプロジェクトメンバテーブルに投入
INSERT INTO project_members (project_id, customer_id, role)
SELECT
((g-1) / 200)::INT + 1 AS project_id, -- 200行ごとにプロジェクトIDが+1(1..1000)
((g-1) % 100000)::INT + 1 AS customer_id, -- 1..100000でローテーション
CASE WHEN random() < 0.5 THEN 'Engineer' ELSE 'PM' END AS role
FROM generate_series(1, 200000) AS g;検証
インデックス生成前後の実行計画(EXPLAIN ANALYZE)を比較してインデックス生成の効果を検証します。
検証①:1カラムのインデックスを生成
プロジェクトメンバテーブルのcutomer_idをWHERE句に設定。
EXPLAIN ANALYZE SELECT * FROM project_members WHERE customer_id = 12345;
出力結果にSeq Scan on project_members(全件走査)が表示されている。
実行時間は42.757ミリ秒。
CREATE INDEX idx_members_customer_id ON project_members(customer_id);プロジェクトメンバテーブルのcutomer_idに対してインデックスを生成。
EXPLAIN ANALYZE SELECT * FROM project_members WHERE customer_id = 12345;
出力結果にIndex Scan using idx_members_customer_idが表示されておりインデックスが活用されている。
実行時間は0.059ミリ秒。
インデックスの活用により実行時間が短くなりました。
検証②:複数カラムのインデックスを生成
プロジェクトメンバテーブルのroleとjoined_atをWHERE句、joined_atをORDER BY句に設定。
EXPLAIN (ANALYZE, BUFFERS)
SELECT project_id, customer_id, role, joined_at
FROM project_members
WHERE role = 'Engineer'
AND joined_at >= CURRENT_DATE - INTERVAL '90 days'
ORDER BY joined_at
LIMIT 200;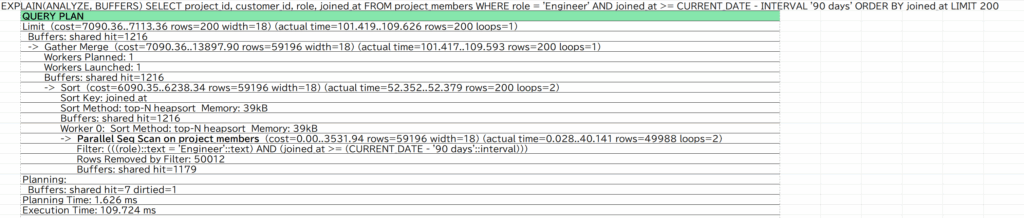
出力結果にParallel Seq Scan on project_members(テーブル全体を並列処理で読み込み)が表示されている。
全体の実行時間は109.626ミリ秒。
CREATE INDEX idx_members_role_joined ON project_members(role, joined_at);プロジェクトメンバテーブルのroleとjoined_atに対してインデックスを生成。
プロジェクトメンバテーブルのroleとjoined_atをWHERE句、joined_atをORDER BY句に設定。
EXPLAIN (ANALYZE, BUFFERS)
SELECT project_id, customer_id, role, joined_at
FROM project_members
WHERE role = 'Engineer'
AND joined_at >= CURRENT_DATE - INTERVAL '90 days'
ORDER BY joined_at
LIMIT 200;
出力結果にIndex Scan using idx_members_role_joined on project_membersが表示されておりインデックスが活用されている。
全体の実行時間は0.181ミリ秒。
複数カラムの指定においてインデックスの活用により実行時間が短くなりました。
検証③:複数カラムのインデックスで1つの項目のみ活用
検証②で生成したidx_members_role_joined(role,joined_atに対するインデックス)を使って、roleのみ、joined_atのみで検索した場合のインデックスの活用を確認します。
EXPLAIN (ANALYZE, BUFFERS)
SELECT project_id, customer_id, role, joined_at
FROM project_members
ORDER BY role
LIMIT 200;
出力結果にIndex Scan using idx_members_role_joined on project_membersが表示されておりインデックスが活用されている。
全体の実行時間は0.138ミリ秒。
EXPLAIN (ANALYZE, BUFFERS)
SELECT project_id, customer_id, role, joined_at
FROM project_members
ORDER BY joined_at
LIMIT 200;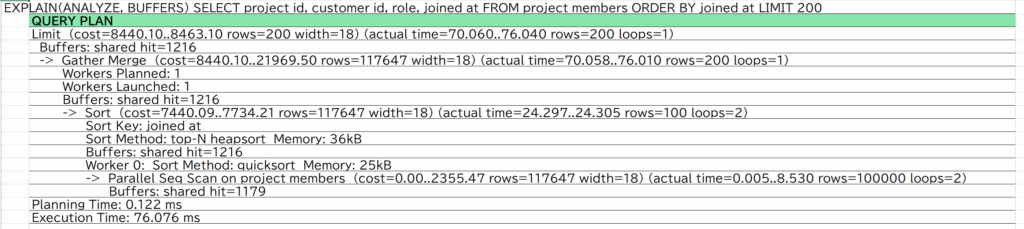
出力結果にParallel Seq Scan on project_members(テーブル全体を並列処理で読み込み)が表示されており、インデックスは活用されていない。
全体の実行時間は76.040ミリ秒。
1項目目のみの場合はインデックスが活用されましたが、2項目目のみの場合はインデックスは活用されませんでした。
これは、左端一致の原則によるもので複合インデックスは先頭カラムから順に検索条件に含まれているときに効果を発揮します。
まとめ:設計段階で「目的」を明確にすることが最重要
PostgreSQLのインデックスは「どのクエリを高速化するためのものか」を明確にしないと、逆に性能を悪化させることがあります。
特に複合主キー・外部キーを含むテーブル設計では、
- 検索パターンの把握
- 結合方向の理解
- 更新頻度とのバランス
を意識した設計判断が不可欠です。
DB関連おすすめ書籍
基礎から実務レベルまで体系的に学べる“DBエンジニア必携の2冊”として特におすすめです。










コメント